AIモデルの性能をどう評価し、どの指標を採用するかは、単なる技術論ではなく“戦略”そのものです。Precision・Recall・F1・BLEUといった指標は、それぞれ異なる意味と役割を持ち、誤用すれば意思決定を誤らせます。本記事では、分類系・生成系タスクにおける指標の本質的な違いと正しい使い分け方、ビジネス要件と結びつけた評価戦略の設計法を体系的に解説します。
第1章:「精度が高い」とは何を意味するのか ― 評価は“戦略”の出発点
🧭 「精度が高い」という言葉に潜む“安心の罠”
「精度が高いモデルです」「正解率95%です」──
こうした数字を見て、「それなら安心だ」と思ってしまった経験はありませんか?
しかし、その“安心感”こそが、AI活用の現場で最も危険な思い込みの一つです。
なぜなら、「精度(accuracy)」という言葉は絶対的な評価ではなく、「何を・どの目的で・どの条件で」測ったかによって意味がまったく変わる相対的な概念だからです。さらに重要なのは、「正解率(accuracy)」と「適合率(precision)」などの評価指標は本質的に異なる意味を持つため、混同すると判断を誤るという点です。
たとえば、同じ「95%の正解率」でも──
医療診断AIでは、5%の誤診が命に関わる致命的なリスクになる
商品レコメンドAIでは、5%の“誤り”が多様性や新しい発見を生む「むしろ価値ある誤差」になる
このように、単なる数値だけを見ても「何が正しく、どこが問題なのか」は分かりません。
本当に見るべきは、「その精度がどのような構造・背景・条件の上に成り立っているのか」という“中身”なのです。
📊 「95%精度」の罠を可視化する
下図は典型的な“数字の罠”の仮想例です(※本記事中の数値はすべて説明目的の想定値です):
指標 値
Accuracy(正解率) 95%
Precision(適合率) 92%
Recall(再現率) 20%
このモデルは「95%正解」と見えますが、実際には「本来検出すべき正解の80%を見逃している」可能性があります。
このように、「Accuracyが高い=実用的」という思い込みは危険です。どの指標が“本質的な価値”を表すかは、タスクや戦略次第なのです。
📊 指標は“スコア”ではなく“戦略の羅針盤”
ここで重要な役割を果たすのが、Precision(適合率)/Recall(再現率)/F1スコアという3つの基本指標です。
これらは単なる「性能の数値」ではなく、モデルの特性やリスク構造、さらには改善の方向性を示す“戦略の羅針盤”として機能します。
Precision(適合率):モデルが「正解」と判定したもののうち、実際に正解だった割合
→ 誤検出(False Positive)を減らす“厳密さ”の指標
Recall(再現率):実際の正解のうち、モデルが正しく検出できた割合
→ 見逃し(False Negative)を防ぐ“網羅性”の指標
F1スコア:PrecisionとRecallの調和平均
→ 双方を統合的に評価し、全体最適を図るための指標
これらが重要なのは、「正答性(Precision)」と「網羅性(Recall)」という本質的にトレードオフ関係にある2軸を同時に扱える数少ない評価体系だからです。
Precisionを上げればRecallは下がり、Recallを重視すればPrecisionは下がる──この構造を理解しなければ、「精度が高い」という言葉の本当の意味を解き明かすことはできません。
💼 なぜ“戦略”と不可分なのか ― 経営・事業判断との接点
ここで忘れてはならないのが、指標の選択は技術判断ではなく、経営判断そのものだという点です。
Precisionを重視するか、Recallを重視するかという選択は、次のような意思決定と直結しています:
Precision重視:誤検出のコストが高い領域(金融、不正検知、医療など)
→ 「リスク最小化戦略」
📊 仮想例:「不正検知AIでPrecisionを95%に高めたと仮定した場合、誤検出対応工数が約30%削減され、年間運用コストが数百万円規模で減る可能性があります。」
Recall重視:見逃しが機会損失につながる領域(広告配信、顧客発掘など)
→ 「市場機会最大化戦略」
📊 仮想例:「潜在顧客検出モデルのRecallを80%→90%に改善したと仮定すると、CV数が約30%増加し、売上が2桁成長するケースもあります。」
つまり、評価指標とは単なる「モデルの点数」ではなく、
どの市場を優先するか
どのリスクを許容するか
どの規制要件に合わせるか
といった事業戦略の根幹を支える判断軸なのです。
⚠️ 指標を誤解すると、戦略も誤る
この基本構造を理解しないまま評価を行うと、現場では次のような典型的な失敗が起こります:
Precision偏重:誤検出は減ったが、肝心な正解をほとんど拾えていない
Recall偏重:正解は拾えるが、誤検出が多すぎて実用性が低い
F1過信:数値上はバランスが取れているが、現場のリスク要件(厳密性 or 網羅性)とズレている
これらはいずれも、「精度の構造を分解していない」ことが原因です。
数値だけを見て評価することは“地図なしで航海する”のと同じであり、方向性を誤ればどんなに高いスコアも役に立ちません。
また、F1スコアはクラス不均衡が大きいタスクでは適切に性能を反映しない場合がある点にも注意が必要です。こうした場合は、Precision-Recall曲線やPR-AUCなどの補助指標を併用することが、実務上の定石です。
「定義」を読み解く力が未来を決める
ここまで見てきたように、「精度が高い」という言葉の背後には、複数の評価軸・トレードオフ・戦略的判断が潜んでいます。
AI活用を真に戦略的なものにするためには、まずこの“精度の中身”を正しく読み解く力が不可欠です。
そして、その第一歩となるのがPrecision/Recall/F1の「定義」を正確に理解することです。
定義の理解を誤れば、評価設計・KPI設計・ROI算出・法規制対応のすべてが歪み、ビジネス上の意思決定にも深刻な影響を与えかねません。
次章では、最も基本でありながら最も誤解されやすい指標、Precision(適合率)から詳しく見ていきましょう。
✅ まとめ ― 評価は“経営戦略”の出発点
「精度が高い」という言葉は相対的であり、背景・条件・リスク構造を抜きにしては意味を持たない。
Precision/Recall/F1 は単なる数値ではなく、事業戦略・市場選択・リスク許容度と密接に結びつく“判断軸”である。
定義を正確に理解することこそが、「AI評価=経営判断」という思考への第一歩である。
✅ この章のゴール:
「精度」はモデルの点数ではない。未来の意思決定を導く羅針盤である──この視点を持てば、AI活用は単なる技術導入から、経営レベルの戦略設計へと進化します。
第2章:Precision/Recall/F1 の正しい読み解き方
🧭 はじめに:Accuracyだけでは“本当の精度”はわからない
AIモデルの「精度」を語るとき、最もよく使われる指標がAccuracy(正解率)です。
しかし、現実のタスクではデータの分布が偏っていることが多く、Accuracyだけでは**「本当に使える性能」**を見誤る可能性があります。
たとえば、不正検知・スパム判定・疾病スクリーニングのように「重要な正例がごく一部しかない」状況では、Accuracyが99%でも肝心の正例をまったく検出できていない場合があります。
こうした現場で役立つのが、Precision(適合率)とRecall(再現率)、そしてそれらを総合的に評価するF1スコアです。
本章では、この3つの指標を定義・読み解き方・トレードオフ・活用指針まで体系的に整理します。
Precision(適合率):誤検出を減らす「厳密さ」の指標
定義:「モデルが正と判定したもののうち、実際に正解だった割合」
$Precision = TP / (TP + FP)$
- TP(True Positive):正解を正と判定した件数
- FP(False Positive):不正解を誤って正と判定した件数
適用例:
- スパム検出(重要なメールを誤ってスパム扱いすると致命的)
- 危険通知・警報システム(誤報が多いと信頼性が低下)
- セキュリティ侵入検知(誤検出が多いと運用コストが爆発)
読み解き方:
Precisionは、**「拾った正解がどれだけ本当に正しかったか」**を測る指標です。
誤検出(FP)を抑えることに強く寄与しますが、Precisionだけを追求すると「正解だけを厳選して拾う」戦略になり、**多くの正解を見逃す(Recall低下)**リスクがあります。
📉 誤用例(仮定シナリオ):
Precisionを高めようと閾値を厳しく設定しすぎた結果、詐欺検知システムが本来の詐欺取引まで見逃し、Recallが0.07まで低下。数千万円規模の損失が発生する可能性があります。
Recall(再現率):見逃しを防ぐ「網羅性」の指標
定義:「実際に正解だったもののうち、モデルが正と判定できた割合」
$Recall = TP / (TP + FN)$
- FN(False Negative):正解を誤って負と判定した件数
適用例:
- 疾患検出(見逃しが患者の命に関わる)
- 不正検知(1件でも見逃すと大損害)
- スクリーニング(できるだけ漏れなく対象を拾いたい)
読み解き方:
Recallは、「本来正解であるものをどれだけ漏らさず拾えたか」を測ります。
「漏れ」が致命的な領域ではRecallを優先すべきですが、Recallを極端に高めると誤検出(FP)が増えてPrecisionが低下するリスクがあります。
📉 誤用例(仮定シナリオ):
Recallを優先しすぎて閾値を下げすぎた結果、スパムフィルタが正規メールまで弾き、誤検出率が大幅に上昇。運用コストが増加するリスクが生じる可能性があります。
トレードオフと閾値設計 ― PrecisionとRecallのバランスを設計する
PrecisionとRecallはしばしばトレードオフの関係にあります:
- 判定閾値を下げる → Recallは上がるがPrecisionは下がる
- 閾値を上げる → Precisionは上がるがRecallは下がる
この関係を理解するための有効なツールがPrecision-Recall曲線です[1]。
横軸をRecall、縦軸をPrecisionとして描くと、モデルの挙動が視覚的に理解できます。
📈 図解イメージ(説明):
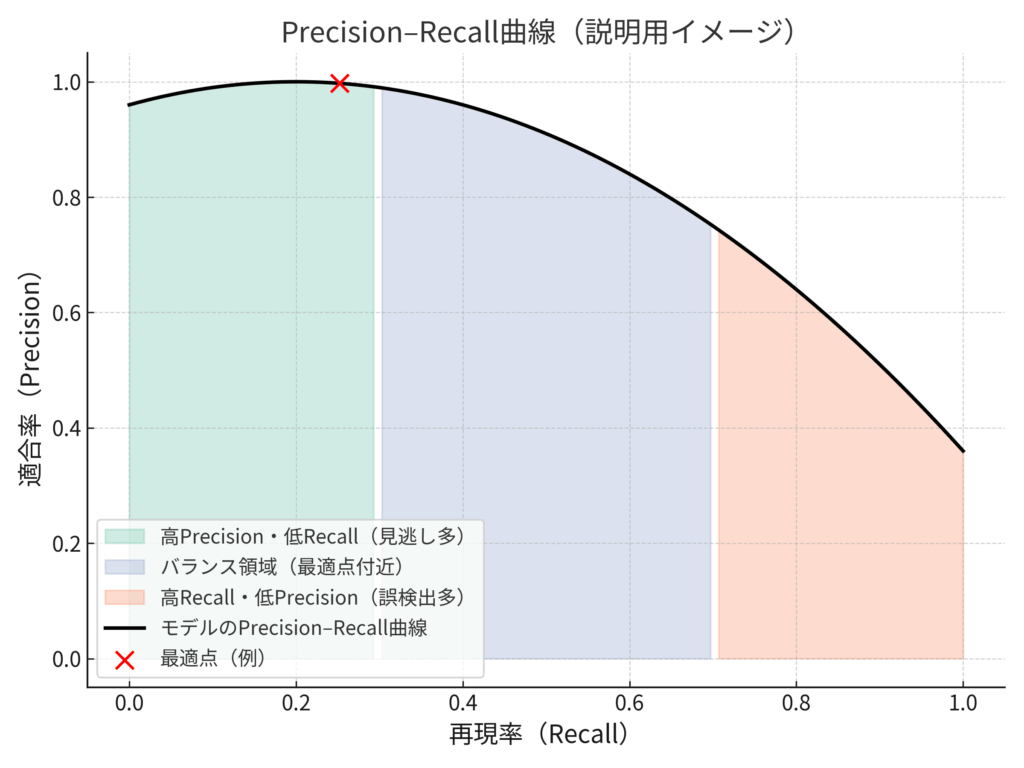
- 左上(高Precision・低Recall):誤検出は少ないが見逃しが多い
- 右下(高Recall・低Precision):多くを拾うが誤検出も増える
中央付近の“要件最適点”を探すことが、実務上の閾値チューニングの本質です。
F1スコア:バランスを測る“共通言語”
PrecisionとRecallの両方が高いモデルこそ、実用性が高いモデルです。
そのバランスを1つの指標で表すのがF1スコアです。
$F1 = 2 × Precision × Recall / (Precision + Recall)$
どちらか一方が著しく低いとF1も低くなり、バランスの良し悪しが直感的に把握できます。
Fβスコア ― 現場要件に応じた重みづけ
タスクによってPrecisionとRecallの重要度は異なります。
そこで、どちらかに重みをつけたFβスコアを使うことがあります。
$Fβ = (1 + β²) × Precision × Recall / (β² × Precision + Recall)$
- β > 1:Recall重視(例:疾病検出、スクリーニング)
- β < 1:Precision重視(例:誤報厳禁の検知タスク)
- β = 1:F1スコア(バランス重視)
📊 Fβスコアの使い分け(参考表)
| タスク | β値 | 重視軸 | 代表ケース |
|---|---|---|---|
| 疾患検出 | 2.0 | Recall重視 | 見逃しが致命傷となる診断系 |
| スパム検出 | 0.5 | Precision重視 | 誤検出がユーザー離脱につながる |
| レコメンド | 1.0 | バランス重視 | 全体最適が求められる推薦システム |
実務的な読み解き方と活用指針
✅ Accuracyだけでは判断しない
→ クラスの偏りがあるタスクではPrecision/Recallが本質的な評価軸になる。
✅ 指標は「ビジネス要件」とセットで考える
→ 「誤報1件で大損害」ならPrecision重視、「見逃し1件が致命傷」ならRecall重視。
✅ F1は“優等生指標”にすぎない
→ 「F1が高い=良いモデル」とは限らず、なぜその重み配分が必要なのかを明確にする。
✅ 目標値の目安(例)*
| タスク | 推奨指標 | 参考値 |
|---|---|---|
| 疾患検出AI | Recall | ≧ 0.95 |
| スパムフィルタ | Precision | ≧ 0.98 |
| レコメンド | F1 | ≧ 0.85 |
*これらは過去の文献・実務報告[1][2]に基づく一例であり、条件・環境により大きく異なります。保証値ではありません。
✅ まとめ:「数値」を“意思決定の言語”にする
Precision/Recall/F1は、単なる性能指標ではありません。
それは、**「どのリスクを許容し、どの成果を優先するか」**という現場判断を数値で可視化する“共通言語”です。
これらを正しく読み解けば、モデル改善の方向性や運用戦略の優先順位が明確になります。
**「精度の高さ」ではなく、「精度指標から何を読み取り、どのように意思決定へ活かすか」**こそが、AI活用を戦略的なレベルへ引き上げる鍵です。
次の章では、本章で整理した指標を実際の改善サイクル・KPI設計・閾値最適化戦略に組み込み、「指標を“戦略設計の出発点”として使う」ための実践フレームを解説します。
📚 参考文献
[1] Saito, T. & Rehmsmeier, M. (2015). “The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets.” PLOS ONE.
[2] Davis, J. & Goadrich, M. (2006). “The Relationship Between Precision-Recall and ROC Curves.” ICML.
第3章:BLEUスコア ― 生成系タスクの評価軸
🧭 はじめに:「正解と“似ている”ことの重要性」
分類や検知タスクでは Precision(適合率)や Recall(再現率)が主要な評価指標として使われます。
しかし、**文章生成系タスク(機械翻訳・要約・対話応答・キャプション生成など)**では、それだけでは出力の質を正確に評価できません。
なぜなら、これらのタスクでは「何を言うか」だけでなく、「どのような表現で言うか」が成果の本質となるためです。
例えば、翻訳モデルが「He went home.」と「He returned home.」のどちらを出力しても意味は同じですが、単純な正解・不正解の判定ではこの違いを捉えられません。
ここで重要になるのが、正解文との表現的な類似度を数値化する指標 ― **BLEU(Bilingual Evaluation Understudy)**スコアです【1】。
🔍 なぜ Precision/Recall では不十分なのか
Precision/Recall は「出力が正解と一致しているかどうか」という**“有無”の評価**に優れますが、「表現の選び方」や「多様な同義表現」の良し悪しを反映することはできません【1】。
生成系タスクでは、以下のような要素が出力品質に大きく影響します:
- 語彙の多様性(例:「good」「excellent」「splendid」など)
- 同義表現・言い換え(例:「went home」「returned home」)
- 構文や語順の選択(例:「He quickly returned home.」など)
こうした**“表現の質的な差”を定量化する**ために登場したのが BLEU です。
📊 分類系 vs 生成系 指標の本質的な違い(比較表)
| 評価観点 | Precision/Recall(分類系) | BLEU(生成系) |
|---|---|---|
| 評価対象 | 正解との一致有無(出力の有無) | 表現の近さ(出力の質) |
| 評価単位 | 個別ラベル・要素単位 | n-gram(連続語句)単位 |
| 表現の多様性 | 評価できない | 同義語・構文選択を反映可能 |
| 適用範囲 | 分類・検知・フィルタリング | 翻訳・要約・キャプションなど生成タスク |
📐 定義:n-gram一致率による「表現類似度」の定量化
BLEUは、2002年にIBMの研究者 Papineni らによって提案された指標で、現在も機械翻訳や自動要約などの研究・ベンチマークで事実上の標準として利用されています【1】。
その本質はシンプルで、モデル出力と参照文(正解文)の n-gram(一連の n 語列)の一致率をもとに「どれだけ表現が近いか」を評価します。
計算式(概要):
$BLEU = BP × exp( Σ (wₙ log pₙ) )$
- pₙ:n-gram の精度(参照文との一致率)
- wₙ:各 n-gram の重み(通常は均等、例:1〜4-gram 各0.25)
- BP:生成文が短すぎる場合のペナルティ(Brevity Penalty)
💡 補足: n-gramの過剰カウントを防ぐクリッピング処理や正規化、派生指標(sBLEU、加重BLEUなど)も実務で用いられます。
📊 BLEUの活用範囲と意味
BLEUスコアは、次のような生成系タスクで広く活用されています【1】【2】:
- 🧠 機械翻訳:生成訳がどれだけ正解訳に近いか
- 📚 自動要約:要約文が参照要約とどの程度一致するか
- 🤖 対話応答・キャプション生成:自然な応答や説明ができているか
スコアは 0〜1(または 0〜100)で表され、**値が高いほど「正解文と表現的に近い」**ことを意味します。
⚠️ 注意点:BLEUは「意味」も「品質」も直接測らない
BLEUは強力な指標ですが、あくまで評価しているのは「表現的な近さ」にすぎません【1】。
以下のような限界があります:
- ❗ 意味の正しさは直接評価しない(表現が似ていても内容が誤っている可能性がある)
- ❗ 文の自然さは評価外(文法や流暢さ、文脈的な適切さは考慮されない)
- ❗ 多様性を反映しにくい(複数の正解表現が存在するタスクでは、参照文が1つだと過小評価される)
例:
参照:「He went home.」
出力:「He returned home.」 → 意味的には正しいが、n-gram一致が低くスコアが下がる
📊 BLEUが“有効に機能する条件”と“機能しない条件”
| 評価条件 | BLEUが有効 | BLEUが不向き・限界あり |
|---|---|---|
| 正解表現が比較的一定 | ✅ 一致率が品質の良否をよく反映 | ❌ 多様な言い回しが評価できない |
| 複数の参照文が用意できる | ✅ 多様性への対応が可能 | ❌ 参照が1つだと過小評価の恐れ |
| 翻訳・要約など“表現の近さ”が重要 | ✅ 定量評価が容易 | ❌ 創作・対話など“創造性”重視の場面では不適切 |
📊 多参照BLEUの効果 ― 一例(参考値)
複数参照の有無で BLEU は大きく変わります。以下は仮想的な例です(実測値ではありません):
| 条件 | BLEUスコア(例) |
|---|---|
| 参照文 1つのみ | 0.42 |
| 参照文 3つ | 0.68 |
同じ出力でも、**「多様な表現を正解とみなせるかどうか」**で評価は大きく変化します。
生成系タスクの評価では、可能な限り複数の参照文を用意することが重要です【1】【3】。
🔧 補完策:他指標との併用で“本当の質”に近づける
BLEUの限界を補うため、実務や研究では以下の指標との組み合わせ評価が一般的です【2】【3】【4】【5】:
| 指標 | 評価対象 | 特徴 |
|---|---|---|
| ROUGE | n-gram の再現率 | 要約タスクに有効。正解文の要素をどれだけ拾えているか |
| METEOR | 語形・同義語を含む意味的類似度 | 同義語や派生形を考慮し、BLEUより柔軟 |
| BERTScore / COMET | 埋め込み空間上の意味類似度 | 高次元の文意味表現を使い、意味の近さを直接評価可能 |
🧰 実務への指針:BLEUは“使い方次第”で真価を発揮する
✅ 評価設計時のチェックポイント:
- BLEUは「表現的な近さ」を測るための指標であり、意味的な妥当性や品質を保証するものではない
- 本当に「使える出力」を評価するためには、ROUGE・METEOR・BERTScoreなどの補完指標と併用することが必須
- 特に複数の正解表現が想定されるタスクでは、参照文を複数用意することで過小評価を防げる
🧪 実務例:BLEU+COMETによる翻訳評価ワークフロー
ステップ①: BLEUで「表現類似度」をスクリーニング(低品質出力の除外)
ステップ②: COMETで「意味的妥当性・文脈適合性」を精査【5】
ステップ③: 人手評価と突き合わせ、改善サイクルへ反映
このような複合評価設計により、「近さ」と「正しさ」の両面から生成モデルを最適化できます。
📚 参考文献
【1】Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002). BLEU: a method for automatic evaluation of machine translation. ACL 2002.
【2】Lin, C. Y. (2004). ROUGE: A package for automatic evaluation of summaries. ACL Workshop.
【3】Banerjee, S., & Lavie, A. (2005). METEOR: An automatic metric for MT evaluation. ACL Workshop.
【4】Zhang, T. et al. (2020). BERTScore: Evaluating Text Generation with BERT. ICLR.
【5】Rei, R. et al. (2020). COMET: A Neural Framework for MT Evaluation. EMNLP.
第4章:タスク別・フェーズ別の指標使い分け戦略
使い分けの戦略 ― タスク別・フェーズ別で変わる最適指標
Precision・Recall・F1・BLEU といった評価指標は、AI活用の現場でほぼ必ず登場します。しかし、「どの指標が最適か」に唯一の正解はありません。
重要なのは、「何を目的に」「どのフェーズで」「どの意思決定を支えるのか」という文脈の中で使い分けることです。
同じ Precision でも、PoC 段階では「改善方向の確認」にすぎませんが、本番運用では「誤検出率=コスト」として直接 ROI に影響します。
つまり、**指標は“静的な評価値”ではなく、“戦略的な改善ループの入力”**として使われてこそ意味を持ちます。
タスク別:業務目的に応じた評価マッピング
まず、タスクごとに「何を守るべきか」「何が致命的か」によって、主軸となる指標はまったく異なります。以下は代表的なマッピングです。
| タスク | 主指標 | 補助指標 | 判断軸 | 典型的な誤り |
|---|---|---|---|---|
| スパム検出 | Precision | Recall | 誤検出が損失につながる | Recallを軽視して重要メールを見逃す |
| 疾患スクリーニング | Recall | Precision | 見逃しが致命的 | Precision偏重で患者を取りこぼす |
| FAQ応答 | Precision/Recall | BLEU | 精度+自然さの両立 | BLEUだけを重視して正答率を無視 |
| 機械翻訳 | BLEU | METEOR/COMET | 表現の自然さ・意味 | BLEU高=高品質と誤解する |
💡 読み方チュートリアル:
- 「Precisionが主指標」=誤検出を防ぐことが重要 → 高PrecisionでもRecallが低ければ改善余地あり。
- 「Recallが主指標」=見逃しが致命的 → Recall向上のために閾値・特徴量・再学習の検討が必要。
- 「BLEUなど表現系」=自然さ・多様性が鍵 → 意味の正確性とのバランス確認が不可欠。
🔎 実務ポイント
- 安全・法務・医療系タスク:Recall が最優先。1件の見逃しが致命的リスクにつながるため。
- 運用・UX系タスク:Precision が重要。誤検出が増えるとシステム自体の信頼性が失われる。
- 生成系タスク:BLEU や METEOR のみで評価せず、正答率(Precision/Recall)との併用が不可欠。
本質は、「どの誤りが最もコストが高いか」を判断軸にすることです。誤検出(False Positive)か見逃し(False Negative)か、どちらが致命的かによって評価軸が逆転します。
フェーズ別:開発ステージによって変わる評価の役割
同じタスクでも、**プロジェクトの進行段階(フェーズ)**によって指標の「読み方」や「重み付け」は大きく変わります。以下は、PoC → 検証 → 本番という3フェーズの典型的な整理です。
| フェーズ | 目的 | 重視指標 | 活用の観点 |
|---|---|---|---|
| PoC段階 | 実現可能性の検証 | Precision/Recall | 成果の方向性や課題の見極め |
| 検証段階 | モデル比較・最適化 | F1/BLEU/AUC | モデル性能の相対評価・閾値調整 |
| 本番運用 | 意思決定・ROI管理 | Precision/Recall+KPI | 誤検出率・見逃し率をコスト・UX指標と連動させる |
🔍 フェーズ別の活用ポイント
- PoC(概念実証):「そもそも自動化が可能か」「現行手法より改善できるか」を見極める段階。数値そのものではなく、数値の意味を読み解くことが重要。
例:Precision が極端に低い → ノイズが多い。Recall が低い → 特徴量が不足。 - 検証段階(開発・比較):複数モデルを比較し、閾値調整や特徴量設計を最適化。F1・BLEU・AUC といった相対評価指標が活躍。
- 本番運用(実装・拡張):指標は単なる性能値ではなく、経営判断の根拠になる。
💡 一例(想定値):「誤検出率を 1% 改善 → 月間オペレーションコストが約30万円削減 → 年間 ROI 約360万円向上」
※実際の効果は環境・条件・モデル特性によって大きく異なります。
⚠️ よくある誤用パターン
- PoCでBLEUだけを評価し「精度が高い」と誤解 → 本番で正答率が低く実装不能。
- 本番でF1のみを追いかけ「ROI効果」を見落とす → コスト削減の機会損失。
タスク × フェーズの交点で考える ― 実践的な指標選定
「タスク別」と「フェーズ別」を別々に考えるだけでは不十分です。重要なのは、その交点で「何を重視すべきか」を定義することです。
| タスク × フェーズ | 初期(PoC) | 検証 | 本番 |
|---|---|---|---|
| 疾患スクリーニング | Recall(見逃し分析) | F1/Recall(閾値調整) | Precision/Recall+コスト連動 |
| スパム検出 | Precision(誤検出除去) | Precision/Recall バランス | Precision+ROI指標 |
| FAQ応答 | Recall(正答網羅性) | BLEU+F1(自然さ+精度) | Precision/BLEU+UX評価 |
| 翻訳 | BLEU(自然さ確認) | BLEU+COMET(意味保持) | BLEU+ROI(再翻訳コストなど) |
生成系タスクの評価マッピング(応用編)
翻訳以外にも、生成系タスクでは評価指標の選定が複雑です。以下は代表例です。
| タスク | 主指標 | 補助指標 | 評価の観点 | 典型的な誤り |
|---|---|---|---|---|
| 要約生成 | Precision/Recall | ROUGE/BERTScore | 抽出漏れ・冗長性 | BLEU偏重で要約の網羅性が損なわれる |
| 画像キャプション | BLEU/METEOR | CIDEr/SPICE | 意味一致・多様性 | 精度指標のみで表現の質を見落とす |
| チャット応答 | Precision/Recall | Human Eval/COMET | 妥当性・一貫性 | 自然さ評価だけで正答率を軽視 |
💡 ポイント: 自動指標だけでなく、**人手評価(Human Eval)**や UXテスト の組み合わせが不可欠です。
※人手評価を行う際は、評価者の同意取得・匿名化・個人情報保護への配慮が必要です。
改善ループを継続する ― 実務フレーム
指標は一度出して終わりではありません。**継続的な改善ループの「フィードバック装置」**として使うことが重要です。
📈 改善ループの実践フレーム:
- 指標計測(Precision/Recall/BLEU など)
- 誤り分析(FP/FN 構造・出力傾向の分類)
- 改善仮説の立案(特徴量・プロンプト・モデル選定など)
- 再学習・再評価(閾値・設計の調整)
- KPIインパクト検証(ROI・UX・オペレーションコスト)
このサイクルを継続して回すことで、**“高スコアのモデル”から“価値を生み続けるモデル”**へと進化します。
✅ まとめ ― 指標を「意思決定の武器」に変える
- **タスクごとに“何が致命的か”**を明確にし、それに応じて指標を選定する。
- **フェーズごとに“指標の役割”**が変わる:PoCでは方向性確認、検証では最適化、本番では経営判断の根拠。
- 指標は“完成度のスコア”ではなく、“改善サイクルを回すためのインプット”として機能させる。
👉 評価指標とは、「AIがどれだけ賢いか」ではなく、「私たちがどのように意思決定すべきか」を導くためのコンパスです。
この視点を持てば、Precision・Recall・BLEU といった数値は、単なる「点数」ではなく、戦略の中心的ツールへと変わります。
📋 実務チェックリスト(導入時の確認用)
- このタスクにおいて、致命的な誤りは何か?(誤検出 or 見逃し)
- 現在のフェーズは何か?(PoC/検証/本番)
- どの指標が「改善のヒント」として役立つか?
- 指標が「ROI」「UX」「コスト」と連動しているか?
- 指標は一度きりで終わっていないか?(改善ループに組み込まれているか?)
📚 補足出典(参考)
- Papineni et al., “BLEU: a Method for Automatic Evaluation of Machine Translation”, ACL 2002
- Davis & Goadrich, “The Relationship Between Precision-Recall and ROC Curves”, ICML 2006
- McKinsey & Company, The State of AI 2024
第5章:「スコア信仰」の落とし穴と対策
よくある誤用と落とし穴 ― 「スコア信仰」が招く失敗
AI活用の現場では、「Precision 95%」「BLEU 0.8」「F1 0.92」といった“高スコア”の数字が並ぶと、つい「モデルは十分に高性能だ」と安心してしまいがちです。
しかし、これは極めて危険な思い込みです。評価指標は「万能な性能の証明」ではなく、「一側面の測定」にすぎません。“測っていない部分”を見落とすと、重大な業務損失や判断ミスにつながります。
ここでは、実務で頻発する「スコア信仰」の典型パターンとその背景、そして避けるための具体策を整理します。
※本章で登場する数値や事例は、評価指標の特徴を説明するための想定例・一般化事例であり、特定の企業・製品・実験結果を示すものではありません。
Precision過信の罠 ― 「正しいものだけ拾うが、ほとんど拾えていない」
Precision(適合率)は、「モデルが検出した正例のうち、本当に正しかった割合」を表す指標です。一見すると高Precisionのモデルは「正確」な印象を与えますが、Recall(再現率)とのバランスを欠くと、“ほとんど拾えていない”モデルになりかねません。
典型例(想定):
- 不正検知モデルが Precision 98% でも Recall が 20% しかなければ、5件中4件の不正を見逃している。
- 医療診断モデルが高Precisionでも、患者の大半を検知できず診断機会を逃す。
実務損失例(一般化):
ある決済事業者で、Precision 98% の不正検知モデルを採用した結果、Recall 20% により大規模な不正取引が検知できず、監査・補償コストが発生したと報告されている。
✅ 本質: Precision は「誤検出しない力」を測っているだけで、「漏れなく拾える力」は測っていません。Precisionだけを追うと、“見逃し放題だが正解率だけ高い”という本末転倒なモデルが生まれます。
BLEU過信の罠 ― 「意味がズレた“それっぽい”出力」
BLEU は自然言語生成タスク(翻訳・要約など)の代表的な指標で、「参照文との表現的一致度」を測定します。しかし、それは“意味の正確性”や“文脈の自然さ”を保証しません。
典型的な失敗例(想定):
- 翻訳タスクで BLEU が高くても、「文意が逆転」「専門用語が誤訳」される。
- 要約タスクで BLEU が高くても、「重要な情報が抜け落ち」「文が不自然」。
実務損失例(一般化):
BLEU 0.85 の翻訳モデルを信頼した結果、契約書中の専門用語が誤訳され、解釈の齟齬から紛争に発展した事例が報告されています。
✅ 本質: BLEU は「言葉の一致度」しか測っていません。意味理解、論理構造、自然性、文脈適合性といった“本当に重要な品質”は測定対象外です。実務では BERTScore や COMET、そして専門家レビューとの併用が不可欠です。
F1偏重の罠 ― 「バランスが取れていても、現場では役に立たない」
F1スコアは Precision と Recall の調和平均で、両者のバランスを示す便利な指標です。しかし、「平均的に良い」というだけでは、業務要件を満たさない場合があります。
典型的な落とし穴(想定):
- 不正検知で「F1 = 0.92」と高くても、実務要件として「Recall 95%以上」が求められれば“失敗”。
- 誤検出が直接コストに結びつく監視システムでは、「Precision の高さ」が最優先で、F1が多少下がっても問題ない。
✅ 本質: F1 は“平均的な性能”を表すだけで、ビジネス要件を反映しません。「Precision重視か」「Recall重視か」といった優先順位を明確にした上で、指標評価軸を設計する必要があります。
誤用が繰り返される心理・組織的背景
誤用は単なる知識不足だけでなく、人や組織の構造的なバイアスによって再生産されます。これらを理解し、制度設計に反映することが“再発防止”の第一歩です。
- KPI圧力バイアス: 「数値=評価」という誤解が蔓延し、指標の高さそのものが目的化する。
- 報酬連動バイアス: 評価・予算・昇進などがスコアと直結し、「本質的な品質」が軽視される。
- レビュー省略バイアス: 自動スコアのみで判断が完結し、専門家レビューが形式的な手続きになる。
よくある誤用の共通構造 ― 「測っていないもの」を見落とす
3つの典型例に共通する本質は、「測っているもの」と「測っていないもの」を混同することです。指標は単一の側面しか反映しないため、次のような“盲点”が発生します。
| 指標 | 測っているもの | 測っていないもの |
|---|---|---|
| Precision | 誤検出しない力 | 検出漏れのリスク |
| Recall | 検出漏れの少なさ | 誤検出コスト |
| BLEU | 表現的一致度 | 意味理解・自然性 |
| F1 | 平均性能 | 業務要件適合性 |
対策①:複合指標を設計する
「単一指標への依存」が最大のリスクです。指標は組み合わせてこそ実務的な意味を持ちます。
| 組み合わせ | 概要 | メリット |
|---|---|---|
| Precision + コスト指標 | Precisionを維持しつつ、誤検出1件あたりの対応コストを算出 | 技術性能と運用コストの両立判断 |
| BLEU + 専門家評価 | 自動スコアとレビュー(意味・文脈適合性)を併用 | 表現・意味・文脈の総合評価 |
| F1 + 業務閾値 | 「Recall 95%以上」など条件付き評価を導入 | 平均性能の“罠”を回避し現場要件に適合 |
対策②:補助指標導入の3ステップ
複合評価を現場に実装するためには、「どの指標をどの順番で導入するか」を明確にすることが重要です。
| ステップ | 内容 | 実務ポイント |
|---|---|---|
| ① 要件整理 | ビジネス側と合意し、「何が最重要か」(例:Recall95%以上など)を明確化 | “高F1”でも失敗の定義が変わる |
| ② 補助指標選定 | Precision+コスト、BLEU+専門家評価など、非測定領域をカバーする指標を追加 | 測定の“穴”を構造的に塞ぐ |
| ③ 検証・PDCA | 自動スコアと補助評価の差異を定期レビューし、閾値・重みを調整 | 「数値信仰」から「要件適合評価」へ転換 |
対策③:「3層チェックリスト」で評価抜け漏れを防ぐ
評価を「戦略判断」「技術評価」「実務運用」の3層で点検すると、盲点を構造的に防げます。
| レイヤー | チェック項目 | 意図 |
|---|---|---|
| 戦略判断層 | ビジネス目的と指標が整合しているか | 誤検出・漏れ・損失など事業インパクト反映 |
| 技術評価層 | 指標の意味と限界を理解しているか | Precision/Recall/BLEU/F1 の測定対象と非対象を把握 |
| 実務運用層 | 補助指標・人間評価を併用しているか | 自動評価だけでなく KPI・UX・専門家レビューを組み合わせているか |
まとめ ― 「数字の高さ」ではなく「条件への適合性」を読む
- Precision が高くても、「正解をほとんど拾えていない」モデルは価値がない。
- BLEU が高くても、「意味がズレた」翻訳は業務で使えない。
- F1 が高くても、「実務上重要な要件」を満たさなければ失敗である。
評価指標は**「手段」であり、「目的」ではありません。**
“数字の高さ”に一喜一憂するのではなく、**「ビジネス上の成功条件にどれだけ適合しているか」**を読み解くことが、AI活用を成功へ導く鍵です。
本章で学んだ「スコア信仰から脱却する視点」は、次章で解説する**「複合評価戦略の設計」や「自動評価パイプライン構築」の基礎**となります。
指標を“数字”としてではなく、“戦略ツール”として使いこなすステージへと進んでいきましょう。次章では、「測っていないものを測る」仕組みを制度として組み込む方法を解説します。
第6章:指標を“意思決定の共通言語”として使う
ここまで見てきた Precision/Recall/F1/BLEU といった評価指標は、単なる「技術スコア」ではありません。
それは、AIを「動かす」ためではなく、「使いこなす」ための羅針盤です。
モデルの出力をただ数値化して終わりではなく、そこから何を読み取り、どう意思決定につなげるか──それこそが、AI活用における評価設計の本質です。
📍 指標は“結果”ではなく“出発点”
多くの現場では、指標が「モデルがうまく動いているかどうか」を示す最終スコアとして扱われがちです。
しかし本来、Precision や Recall は「現状の課題を可視化する手段」であり、改善の入口にすぎません。
- Precision が低い → 誤検出が多い。入力設計やデータ品質、前処理ロジックを見直すべき。
- Recall が低い → 見逃しが多い。特徴量設計や判定閾値、データバランスの再検討が必要。
- BLEU が低い → 表現が不自然。訓練データの質や生成条件、モデルサイズを再考する必要がある。
たとえば、翻訳モデルで BLEU が高くても、文脈的に不自然な訳語が多ければ、ユーザー体験は損なわれます。
**数値は「良し悪しの判定」ではなく、「次のアクションを決定するトリガー」**としてこそ価値を持つのです。
🧭 「次に何を最適化すべきか」の判断フレーム
評価は単なる“数字の報告”ではなく、次のアクションを導く意思決定の指針です。以下は、現場で使える簡易判断フレームです:
| 状況 | 主な課題 | 優先アクション |
|---|---|---|
| Precision低下 | 誤検出コスト上昇 | 閾値再調整・特徴量精査 |
| Recall低下 | 見逃しによる機会損失 | データ拡充・モデル再学習 |
| BLEU低下 | 表現の不自然さ | 生成条件・学習データ改善 |
このような「数値→原因→対応」構造を明確にしておくことで、改善計画が迷わず立てられます。
📊 「指標を上げること」が目的ではない
評価指標の本質は、「数字を競う」ことではありません。
むしろ、「数字から本質的な改善方針を読み解き、業務価値に変換すること」にあります。
- F1 を 0.85 → 0.9 に上げても、ROI が変わらないなら意味がない。
- BLEU が高くても、UX が低下すれば失敗。
- Recall が下がっても、Precision の向上で誤検出対応コストが半減するなら、それは成功。
重要なのは、「何を最適化すべきか」という戦略的な判断軸を持つことです。
数値そのものではなく、「数値がビジネス・運用・UXにどう影響するか」を読み解く姿勢が欠かせません。
🔗 技術指標 × ビジネス指標 × ユーザー体験 の統合
評価設計の理想は、技術スコアだけで完結するのではなく、ビジネス指標(KPI)やユーザー体験(UX)と一体で設計されている状態です。
| 評価レイヤー | 例 | 意味するもの |
|---|---|---|
| 技術指標 | Precision/Recall/BLEU | モデルの性能(内部品質) |
| ビジネス指標 | ROI/コスト削減率/CVR | 成果への貢献度(経営インパクト) |
| ユーザー指標 | 満足度/操作時間/エラー率/NPS | 利用体験(価値実感) |
この3つが一貫して「同じ方向」を向いているとき、評価は単なる測定ではなく、戦略ツールとして機能します。
逆に、技術指標だけが向上しても、ビジネス効果や UX が伴わなければ、それは自己満足的な最適化にすぎません。
📈 KPI連動の改善サイクル ― 数値の“意味”をビジネス価値に変える
評価指標は、「数値が上がった/下がった」で終わるのではなく、「価値創出の連鎖」を明確に描く必要があります。以下はその一例です:
📊 数値物語化のテンプレート(※あくまで想定例)
- Precision:0.85 → 0.95
- ↓
- 誤検出件数:1,000件/月 → 700件/月(−30%)
- ↓
- 対応工数:300h/月 → 210h/月(−30%)
- ↓
- 年間コスト削減:480万円(ROI +18%)
※上記は仮想的な想定シナリオであり、実際の効果はデータ・モデル・運用条件によって異なります。
このような「数値のストーリー化」ができて初めて、評価は経営判断とつながります。
🔄 自動評価パイプライン ― 継続的改善の基盤をつくる
自動評価とは、「モデル更新のたびに指標を自動測定し、改善状況を可視化・フィードバックする仕組み」です。
これにより、評価は単発イベントではなく、継続的な改善プロセスへと進化します。
📊 構成イメージ
[データ入力] → [推論] → [自動評価(Precision/Recall/BLEU測定)]
↓
[改善レポート生成・アラート]
↓
[再学習・閾値調整・再デプロイ]
このループが組み込まれることで、**「モデル精度の変化 → 業務KPIへの影響 → 改善行動」**が自動化され、チーム全体の改善速度が飛躍的に向上します。
✅ 導入チェックリスト ― 評価を「戦略の言語」にするために
| チェック項目 | 状態 |
|---|---|
| 評価指標とKPIのマッピングが定義されているか | ✅ / ❌ |
| 自動測定・レポート生成がCI/CDに組み込まれているか | ✅ / ❌ |
| UX指標(満足度・操作時間など)がビジネス指標と連動しているか | ✅ / ❌ |
| 指標が閾値を超えた際のアクションルールが明文化されているか | ✅ / ❌ |
| 定期的な評価レビューと改善サイクルが運用されているか | ✅ / ❌ |
✅ まとめ
- Precision/Recall/BLEU は、単なる技術指標ではなく、意思決定の共通言語である。
- 「スコアを上げること」が目的ではなく、「スコアから“何を読み取り、どう行動するか”」が本質。
- 技術・ビジネス・UX を統合して初めて、評価は“戦略ツール”としての力を発揮する。
- 自動評価と KPI 連動によって、評価は現場の判断・経営の判断・改善の判断をつなぐ中核機能へと進化する。
評価指標は、AIを測る「物差し」ではなく、**組織を動かす“言語”**である。
この視点を持てば、AI導入は単なる技術導入ではなく、戦略と意思決定の進化へとつながっていくのです。
📊 応用例:戦略言語としての活用
- 月次経営会議のKPIダッシュボードに自動評価レポートを統合
- 新機能ローンチ時のUXレビューと指標分析を接続
- 機械学習パイプラインに「閾値アラート → 改善チケット自動生成」を組み込む
📜 免責事項
本記事は一般的な情報提供を目的としたものであり、記載された数値・事例・効果等は一部想定例を含みます。内容の正確性・完全性を保証するものではありません。詳細は利用規約をご確認ください。
